Congestion Avoidance is a set of mechanisms designed to prevent packet loss before it happens.
When more packets arrive at an outgoing interface than it can transmit, the excess is stored in its output queue. If the queue becomes full, new packets are dropped. This not only reduces performance but also triggers unnecessary TCP slowdowns.
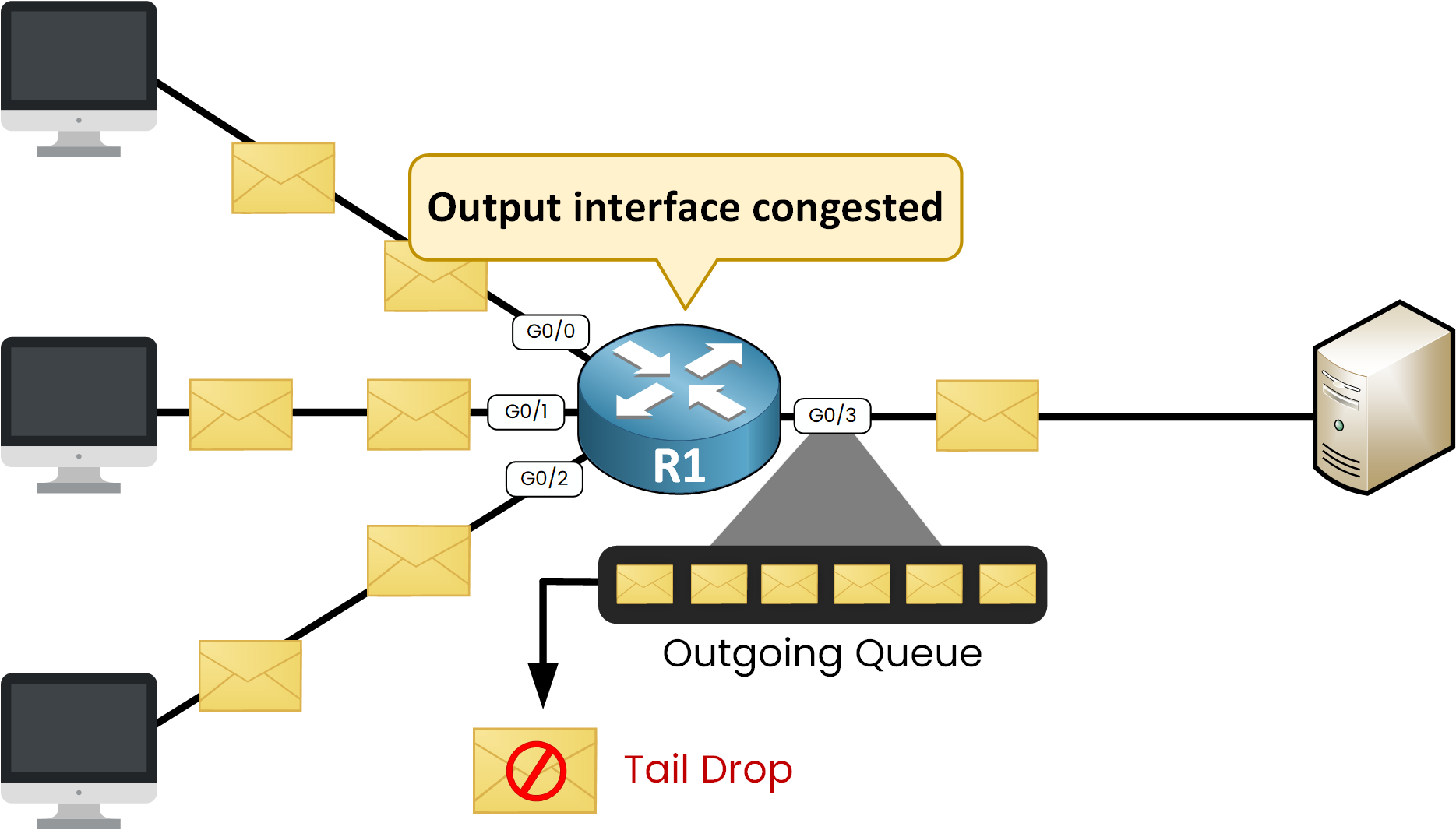
Figure 1 – Outgoing Interface congestion
As the name suggests, the goal of congestion avoidance is to prevent congestion before it happens.
Before exploring these mechanisms, it is important to first understand how TCP windowing works, since TCP’s behavior directly interacts with congestion.
Answer the question below
TCP uses a mechanism called TCP windowing to control how much data the sender can transmit before waiting for acknowledgments.
How It Works
Slow Start – The sender begins cautiously by transmitting just 1 segment.
Acknowledgment (ACK) – Once the receiver confirms delivery, the sender doubles the number of segments for the next round.
Exponential Growth – With each ACK, the number of segments doubles (2, 4, 8…), allowing the transmission rate to increase very quickly.
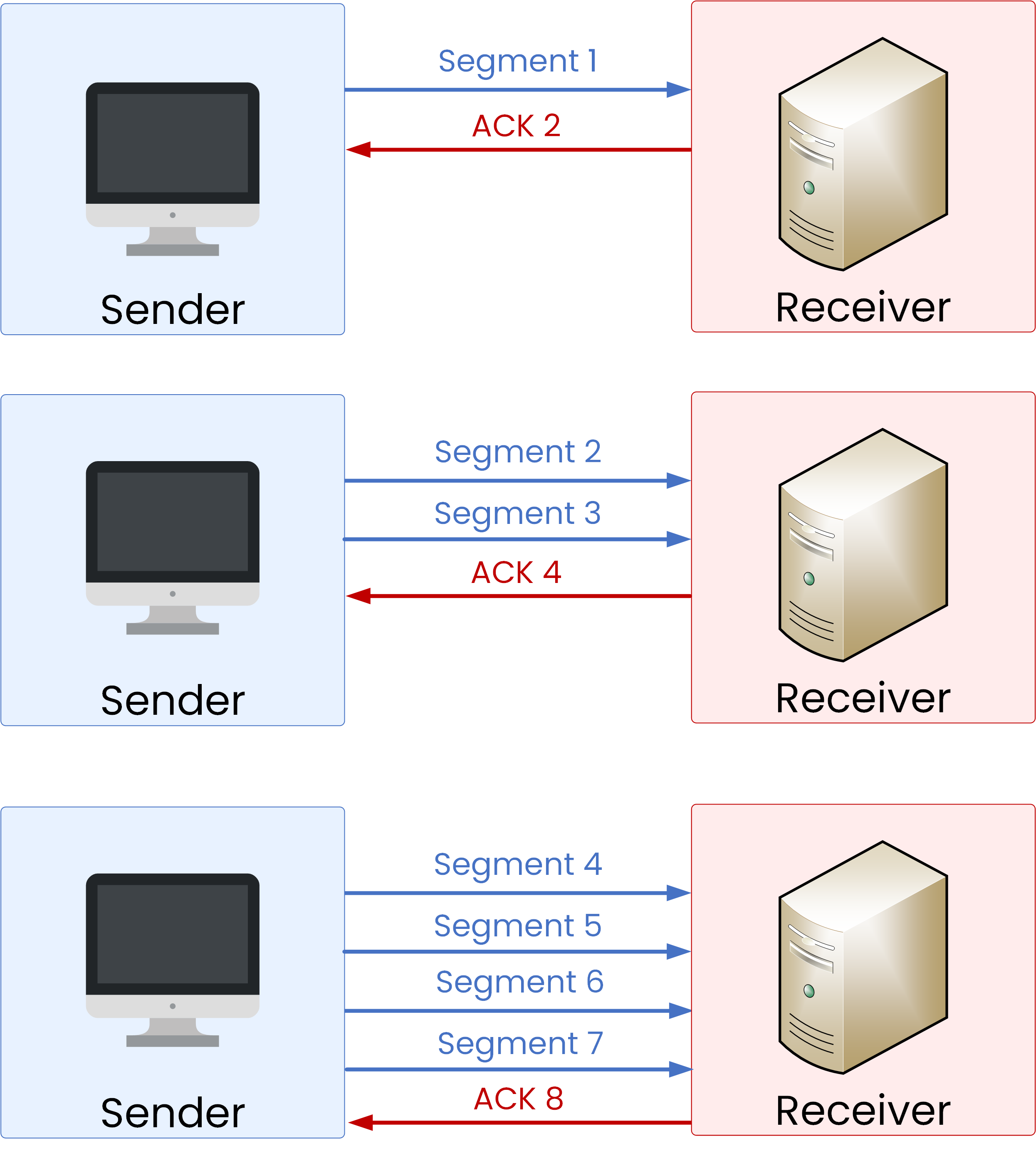
Figure 2 – TCP windowing process.
This exponential growth continues until the network or the receiver cannot keep up with the flow of data.
Now let's see how TCP reacts when the server cannot keep up with the flow.
Packet Loss
Suppose the sender transmits Segments 8–15:
Segments 8–11 arrive successfully.
Segments 12–15 are lost due to congestion.
The receiver responds with ACK 12, confirming it has received everything up to Segment 11 but is still waiting for Segment 12.
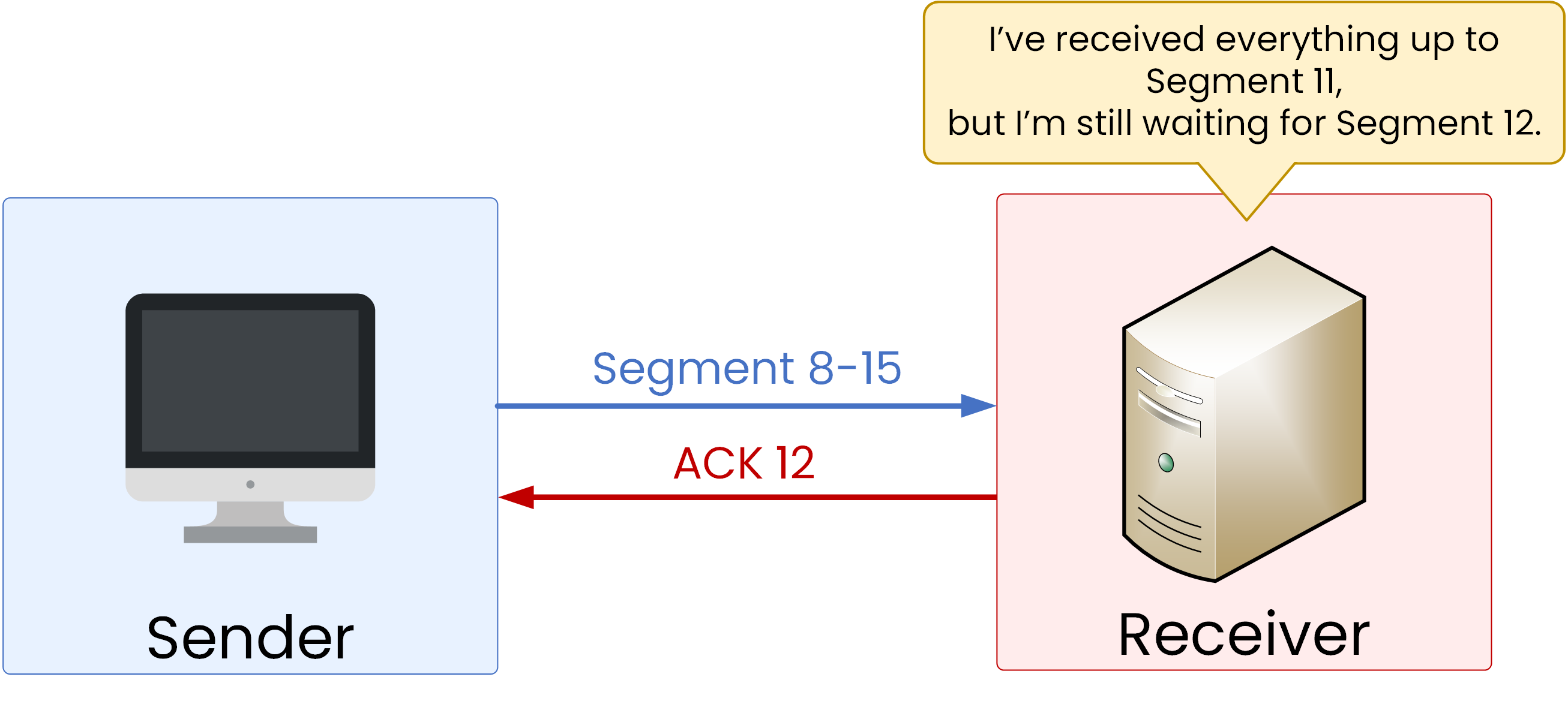
Figure 3 – TCP packet loss and acknowledgment
TCP’s Reaction to Packet Loss
When TCP detects the loss:
It immediately reduces its congestion window by half.
Before the loss: 8 segments in flight.
After the loss: 4 segments in flight.
The sender retransmits the lost packets (12–15).
Once they are delivered, the receiver replies with ACK 16, and normal transmission resumes.
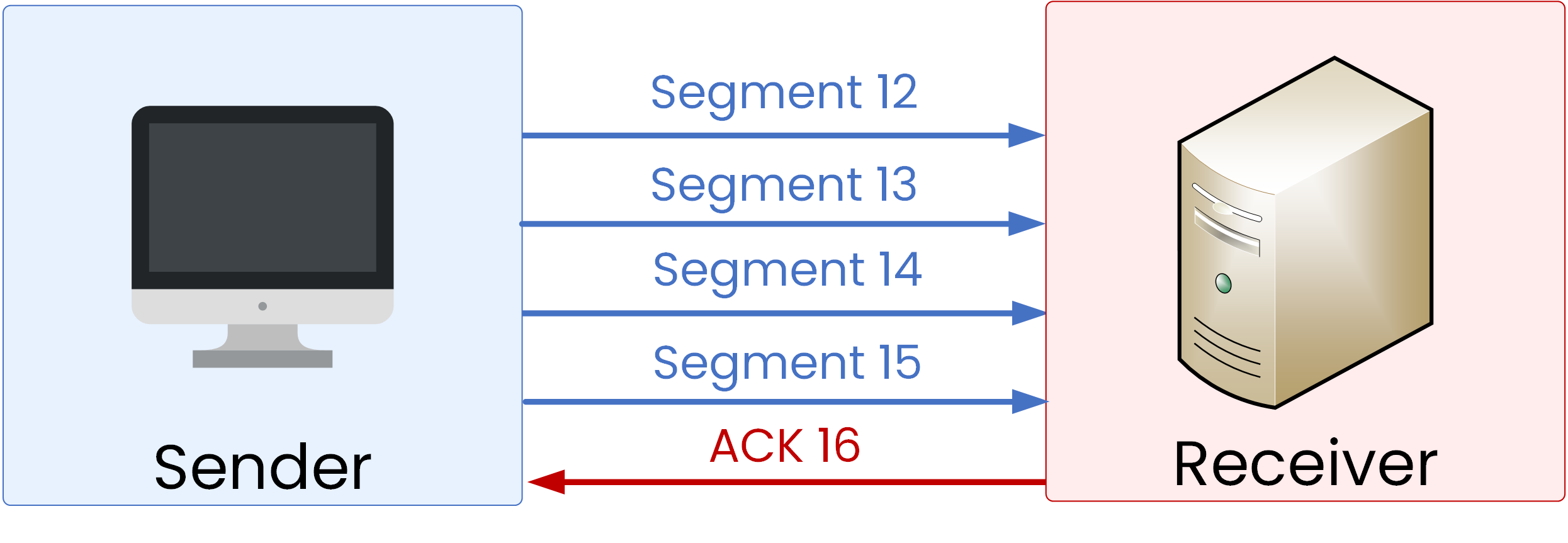
Figure 4 – TCP retransmission of lost segments.
Impact of Packet Loss on TCP Behavior
TCP interprets packet loss as a sign of network congestion. Each time it happens, TCP slows down by cutting its sending rate in half.
The issue is that not all packet losses come from true congestion. In many cases, the loss happens because a device’s output queue becomes full. When that queue overflows, packets are dropped even though the network itself may still have available capacity.
Answer the question below
What does TCP use to control how much data it can send?
We’ve seen that TCP reacts to packet loss by reducing its window size. But where do those losses come from?
In many cases, they are not caused by true network overload, but by a full output queue on a device.What is Network Congestion?
Network congestion happens when traffic arriving at a device is greater than what its outgoing interface can forward.
40 % Complete: you’re making great progress
Ready to pass your CCNA exam?